Hook-InlineHook
本文首发于蚁景网安
前言
导入地址表钩取的方法容易实现但是存在缺陷,若需要钩取的函数不存在导入地址表中,那么我们就无法进行钩取,出现以下几种情况时,导入函数是不会存储在导入地址表中的。
- 延迟加载:当导入函数还没调用时,导入函数还未写入到导入地址表中。
- 动态链接:使用
LoadLibrary与GetProcAddress函数时,程序是显式获取函数地址的,因此不会写入到导入地址表中。 - 手动解析导入函数:即程序自身实现一套导入方法,那么此时也不会将导入函数写入到导入地址表中。
有一种钩取方法解决上述问题即内联钩取(inline hook)。
内联钩取(inline hook)
内联钩取实际是找到需要钩取的函数地址,这里与导入地址表钩取不同的是我们不在局限于导入地址表,而是程序中所有的函数地址都能够作为钩取的对象。
这里以CreateProcessW函数为例,在CreateProcessW函数中,第一条指令是mov edi,edi
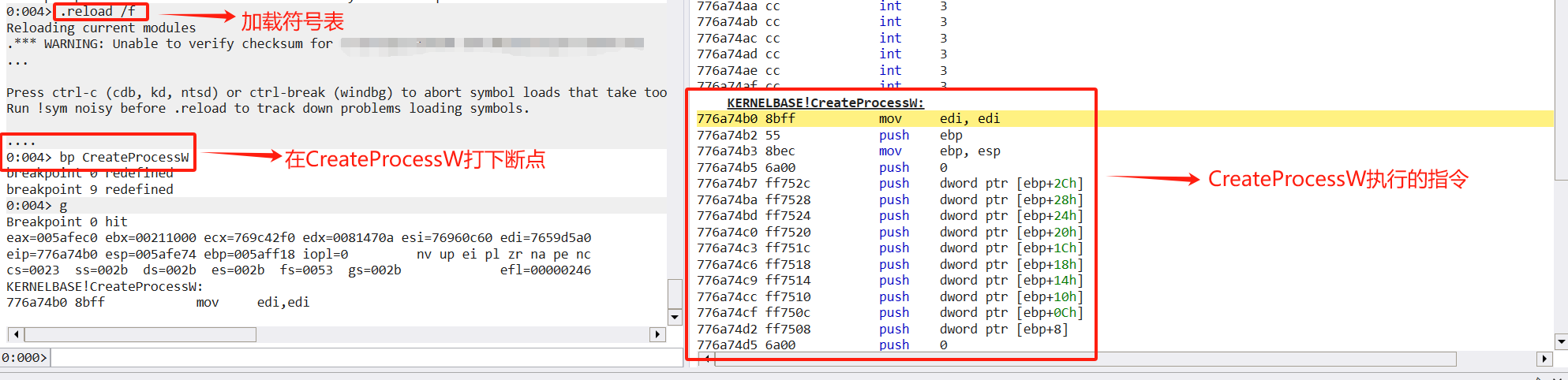
那么根据钩取的思路,我们将mov edi,edi这条指令修改为jmp xxx(xxx为我们自定义函数的地址),那么在执行CreateaProcessW函数时即可跳转到我们的自定义函数中。
我们获取mov edi,edi指令的地址,并且将该指令篡改为jmp指令,并且把mov edi,edi指令的数据进行存储,那么在执行到CreateProcessW函数时就会执行jmp指令跳转到自定义函数中,在钩取操作时需要将指令写回,还原CreateProcessW函数的执行逻辑,就可以在钩取的同时无碍的执行程序。
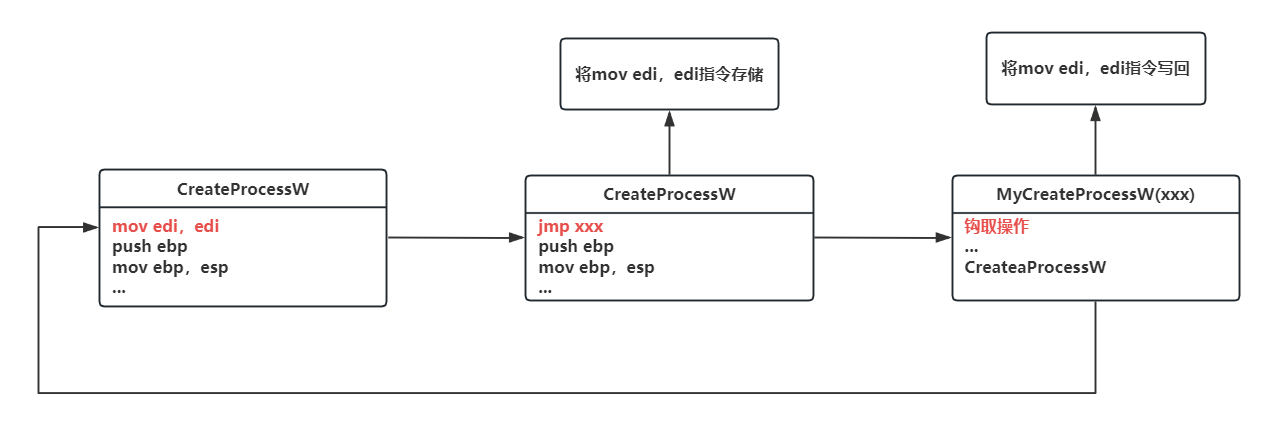
那么总结一下内联钩取函数的流程
- 找到需要钩取的函数的指令地址,这个指令并不仅限于函数起始的指令。
- 将该指令篡改成跳转指令,跳转的目的就是自定义的函数。
- 在自定义函数内需要还原被钩取函数的指令。
因此内联钩取的实际就是修改程序执行逻辑,劫持程序的执行流程。由于32位程序与64位程序的汇编语言与寻址方式有些许差异,因此不同机器位数的程序的内联钩取方式不同。
机器码的获取
由于在篡改内存时需要将jmp xxx的机器码填写到内存中,因此做内联钩取时需要获取指令对应的机器码。在C语言中支持内联汇编,因此可以使用内联汇编然后查看对应的机器码即可。
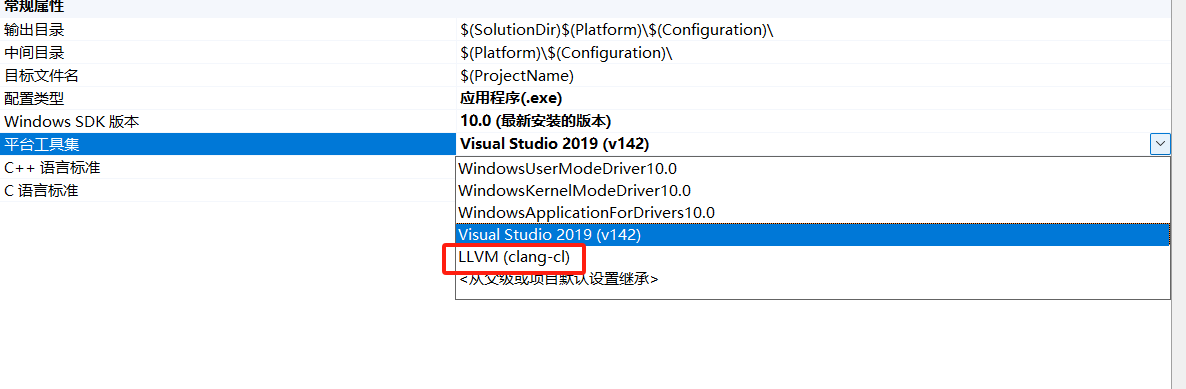
但是直接使用visual studio编译64位程序的内联汇编代码会出错,这是因为visual studio自带的编译工具不支持x64的内联汇编。
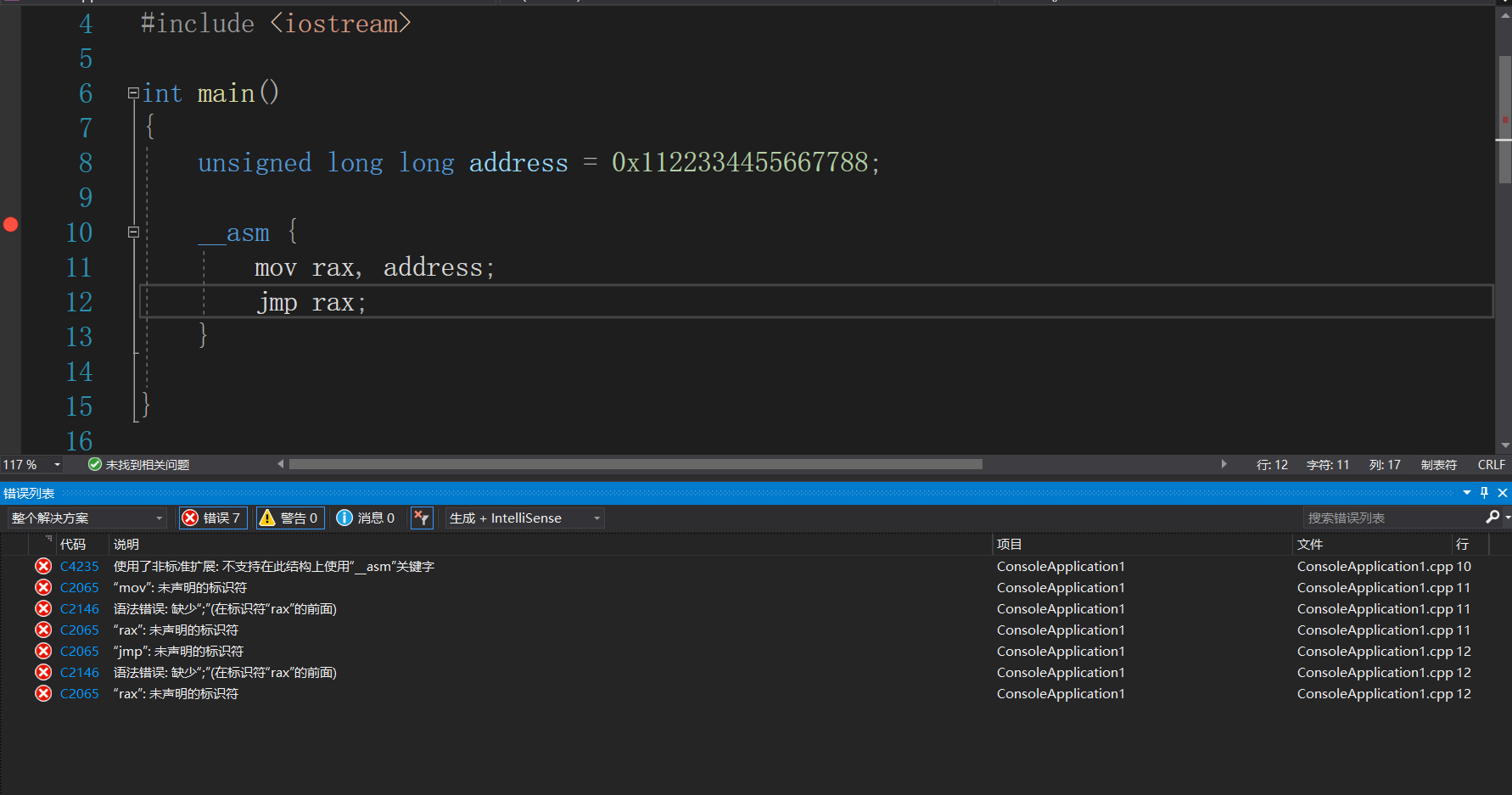
因此需要先安装clang编译器
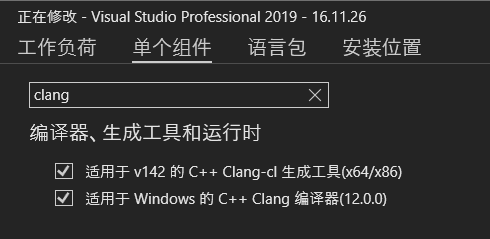
在项目的编译工具选择clang即可
在反汇编窗口中就有机器码了。
32位的内联钩取
首先第一步是确定在32位程序下是如何进行跳转的,在32位情况使用跳转指令是根据偏移获取目的地址,偏移的计算公式如下
跳转偏移 = 跳转目的地址 - 当前指令地址 - 指令长度
因此jmp xxx中,xxx是偏移值而不是目的函数的绝对地址。
紧接着需要确定在32位下跳转指令的机器码是多少,用下面例子看看
1 | |
可以看到对应的机器码为E9 EB FF FF FF

可以看到目标函数的地址为0xA71000,使用上述公式计算一下偏移为0xA71000 - 0x0A71010 - 5 = 0xffffffeb,因此E9为jmp的机器码
因此需要将待钩取函数的第一条指令修改为E9 XX XX XX XX XX,长度为5个字节
然后选择一个目标函数,这里还是使用CreateProcessW函数作为例子,需要先获取CreateProcessW函数的地址
1 | |
然后需要保存原始指令,然后修改区域为可写权限,紧接着计算一下偏移把完整的指令写进到待钩取函数即可。
1 | |
64位的内联钩取
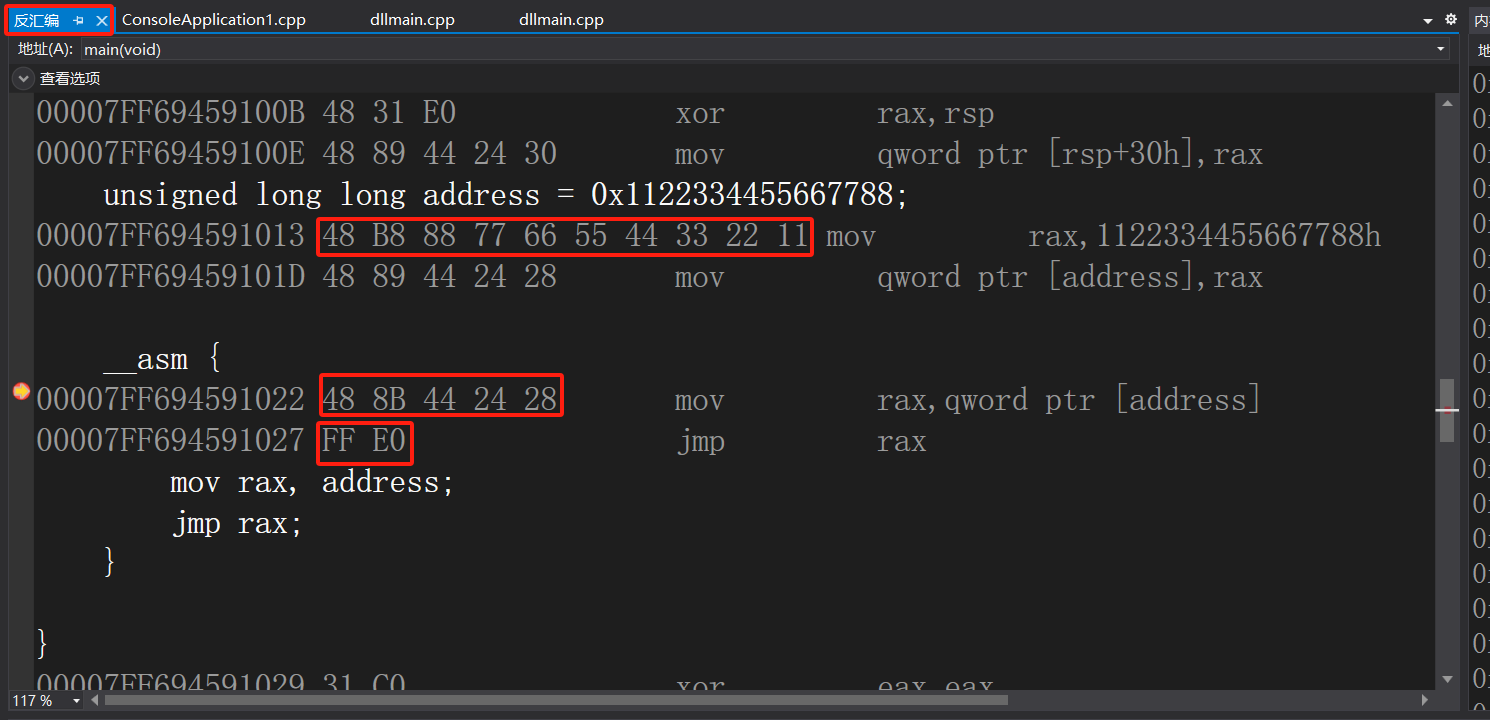
64位下的规则会与32位有差异,但是总体思路是一致的。在32位下我们采用了偏移的方式找到目标函数,在64位下可以换种方式,采用mov rax, xxx; jmp rax,将函数的绝对地址写入寄存器,然后跳转到指定寄存器的方式。
如下例子,我们首先获取自定义函数的绝对地址,紧接着将它存放于寄存器中,紧接着跳转即可。
1 | |
可以看到mov rax, xxx; jmp rax指令的机器码为48 B8 xx xx xx xx xx xx xx xx FF E0,其中由于64位地址都是8字节的,因此需要xx需要填充8字节

因此总体代码与32位区别不大,这里需要注意的是篡改的指令长度需要根据实际进行更改。
1 | |
因此任意可以修改函数执行流程的汇编指令实际都可以例如push xxx; ret。
完整代码可以参考https://github.com/h0pe-ay/HookTechnology/tree/main/Hook-InlineHook
总结
优势
- 内联钩取相较于导入表钩取的选择性更广,可以选择任意的函数及函数内的任意指令地址。
劣势
- 每次都需要脱钩后再进行挂钩,影响效率
- 多线程写入时可能会出错
参考链接
《逆向工程核心原理》